Building Explicit World Model for Zero-Shot Open-world Object Manipulation
Abstract
Open-world object manipulation has emerged as a popular research frontier in robotics. While recent advances in vision-language-action (VLA) models have achieved impressive results, they typically rely on large amounts of task-specific action data for training. This thesis aims to enable a manipulator to perform open-world object manipulation tasks without any action demonstrations. Instead of learning direct action mappings, we focus on explicitly modeling object dynamics via an explicit world model.
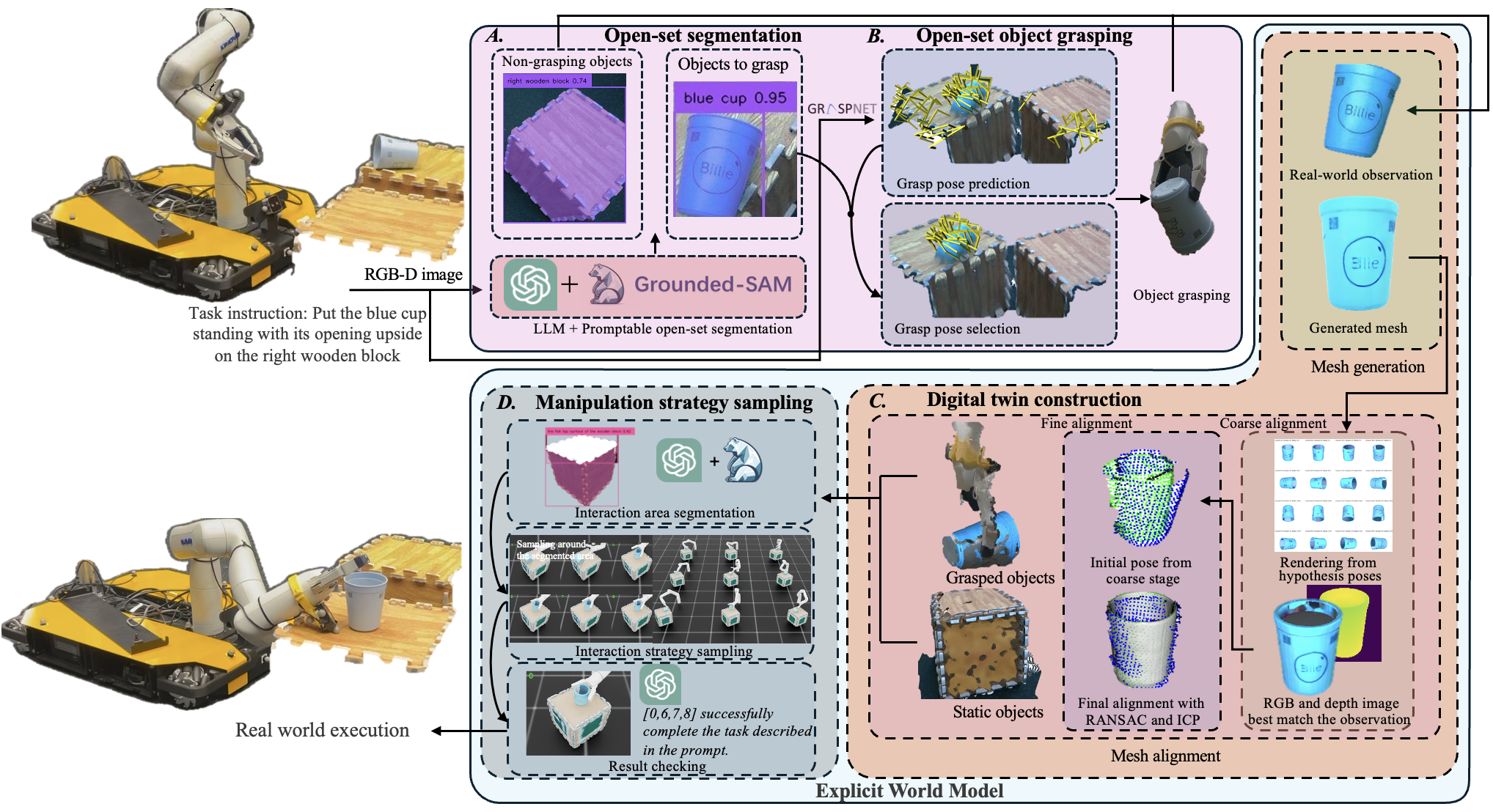
We propose a framework that builds an explicit world model for zero-shot open-world object manipulation. The framework integrates open-set segmentation and grasping, 3D digital twin reconstruction, and simulation-based strategy sampling within a unified pipeline. At the core of our approach lies the construction of a physically grounded digital twin of the environment, which enables the framework to simulate and evaluate diverse interaction strategies before real-world execution.
Experimentally, the proposed framework is able to perform multiple open-set manipulation tasks, such as "put the banana into the basket", "stack the green cube onto the yellow cube", and "place the blue cup upside down on the wooden box". These results are obtained without any task-specific action demonstrations, demonstrating strong generalization and autonomy compared to existing closed-set or imitation-based systems.
Put an object into a container
Stack objects
Fine instruction understanding